Trends and cycles in unemployment¶
Here we consider three methods for separating a trend and cycle in economic data. Supposing we have a time series \(y_t\), the basic idea is to decompose it into these two components:
where \(\mu_t\) represents the trend or level and \(\eta_t\) represents the cyclical component. In this case, we consider a stochastic trend, so that \(\mu_t\) is a random variable and not a deterministic function of time. Two of methods fall under the heading of “unobserved components” models, and the third is the popular Hodrick-Prescott (HP) filter. Consistent with e.g. Harvey and Jaeger (1993), we find that these models all produce similar decompositions.
This notebook demonstrates applying these models to separate trend from cycle in the U.S. unemployment rate.
[1]:
%matplotlib inline
[2]:
import numpy as np
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
[3]:
from pandas_datareader.data import DataReader
endog = DataReader('UNRATE', 'fred', start='1954-01-01')
Hodrick-Prescott (HP) filter¶
The first method is the Hodrick-Prescott filter, which can be applied to a data series in a very straightforward method. Here we specify the parameter \(\lambda=129600\) because the unemployment rate is observed monthly.
[4]:
hp_cycle, hp_trend = sm.tsa.filters.hpfilter(endog, lamb=129600)
Unobserved components and ARIMA model (UC-ARIMA)¶
The next method is an unobserved components model, where the trend is modeled as a random walk and the cycle is modeled with an ARIMA model - in particular, here we use an AR(4) model. The process for the time series can be written as:
where \(\phi(L)\) is the AR(4) lag polynomial and \(\epsilon_t\) and \(\nu_t\) are white noise.
[5]:
mod_ucarima = sm.tsa.UnobservedComponents(endog, 'rwalk', autoregressive=4)
# Here the powell method is used, since it achieves a
# higher loglikelihood than the default L-BFGS method
res_ucarima = mod_ucarima.fit(method='powell', disp=False)
print(res_ucarima.summary())
/home/travis/build/statsmodels/statsmodels/statsmodels/tsa/base/tsa_model.py:162: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
% freq, ValueWarning)
Unobserved Components Results
==============================================================================
Dep. Variable: UNRATE No. Observations: 791
Model: random walk Log Likelihood 255.062
+ AR(4) AIC -498.124
Date: Tue, 17 Dec 2019 BIC -470.092
Time: 23:38:18 HQIC -487.349
Sample: 01-01-1954
- 11-01-2019
Covariance Type: opg
================================================================================
coef std err z P>|z| [0.025 0.975]
--------------------------------------------------------------------------------
sigma2.level 0.0175 0.003 6.405 0.000 0.012 0.023
sigma2.ar 0.0106 0.003 3.515 0.000 0.005 0.016
ar.L1 1.0404 0.066 15.764 0.000 0.911 1.170
ar.L2 0.4727 0.104 4.525 0.000 0.268 0.677
ar.L3 -0.3404 0.127 -2.686 0.007 -0.589 -0.092
ar.L4 -0.1832 0.077 -2.371 0.018 -0.335 -0.032
===================================================================================
Ljung-Box (Q): 75.97 Jarque-Bera (JB): 44.03
Prob(Q): 0.00 Prob(JB): 0.00
Heteroskedasticity (H): 0.49 Skew: 0.25
Prob(H) (two-sided): 0.00 Kurtosis: 4.05
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Unobserved components with stochastic cycle (UC)¶
The final method is also an unobserved components model, but where the cycle is modeled explicitly.
[6]:
mod_uc = sm.tsa.UnobservedComponents(
endog, 'rwalk',
cycle=True, stochastic_cycle=True, damped_cycle=True,
)
# Here the powell method gets close to the optimum
res_uc = mod_uc.fit(method='powell', disp=False)
# but to get to the highest loglikelihood we do a
# second round using the L-BFGS method.
res_uc = mod_uc.fit(res_uc.params, disp=False)
print(res_uc.summary())
/home/travis/build/statsmodels/statsmodels/statsmodels/tsa/base/tsa_model.py:162: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
% freq, ValueWarning)
Unobserved Components Results
=====================================================================================
Dep. Variable: UNRATE No. Observations: 791
Model: random walk Log Likelihood 219.139
+ damped stochastic cycle AIC -430.277
Date: Tue, 17 Dec 2019 BIC -411.599
Time: 23:38:20 HQIC -423.097
Sample: 01-01-1954
- 11-01-2019
Covariance Type: opg
===================================================================================
coef std err z P>|z| [0.025 0.975]
-----------------------------------------------------------------------------------
sigma2.level 0.0142 0.005 2.823 0.005 0.004 0.024
sigma2.cycle 0.0172 0.005 3.514 0.000 0.008 0.027
frequency.cycle 0.0698 0.005 13.602 0.000 0.060 0.080
damping.cycle 0.9896 0.004 240.610 0.000 0.982 0.998
===================================================================================
Ljung-Box (Q): 170.72 Jarque-Bera (JB): 85.76
Prob(Q): 0.00 Prob(JB): 0.00
Heteroskedasticity (H): 0.48 Skew: 0.47
Prob(H) (two-sided): 0.00 Kurtosis: 4.31
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Graphical comparison¶
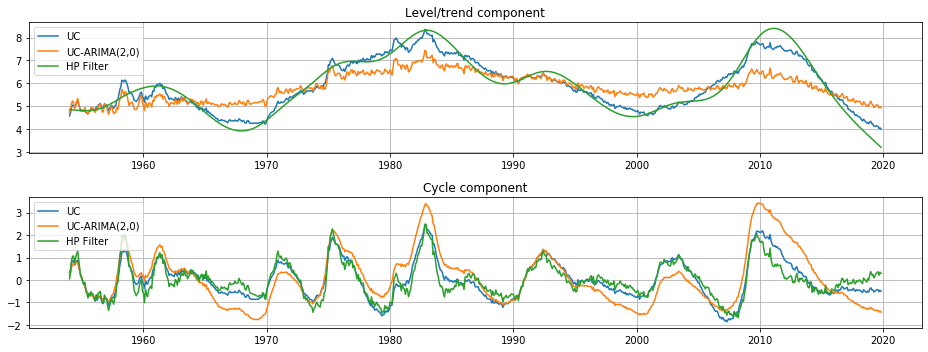
The output of each of these models is an estimate of the trend component \(\mu_t\) and an estimate of the cyclical component \(\eta_t\). Qualitatively the estimates of trend and cycle are very similar, although the trend component from the HP filter is somewhat more variable than those from the unobserved components models. This means that relatively mode of the movement in the unemployment rate is attributed to changes in the underlying trend rather than to temporary cyclical movements.
[7]:
fig, axes = plt.subplots(2, figsize=(13,5));
axes[0].set(title='Level/trend component')
axes[0].plot(endog.index, res_uc.level.smoothed, label='UC')
axes[0].plot(endog.index, res_ucarima.level.smoothed, label='UC-ARIMA(2,0)')
axes[0].plot(hp_trend, label='HP Filter')
axes[0].legend(loc='upper left')
axes[0].grid()
axes[1].set(title='Cycle component')
axes[1].plot(endog.index, res_uc.cycle.smoothed, label='UC')
axes[1].plot(endog.index, res_ucarima.autoregressive.smoothed, label='UC-ARIMA(2,0)')
axes[1].plot(hp_cycle, label='HP Filter')
axes[1].legend(loc='upper left')
axes[1].grid()
fig.tight_layout();
/home/travis/miniconda/envs/statsmodels-test/lib/python3.7/site-packages/pandas/plotting/_matplotlib/converter.py:103: FutureWarning: Using an implicitly registered datetime converter for a matplotlib plotting method. The converter was registered by pandas on import. Future versions of pandas will require you to explicitly register matplotlib converters.
To register the converters:
>>> from pandas.plotting import register_matplotlib_converters
>>> register_matplotlib_converters()
warnings.warn(msg, FutureWarning)